
Hi, I'm Aditya Gurung
Data Engineer | Freelancer
Lead Data Engineer with a decade of experience in building and deploying scalable ELT pipelines in production. Orchestration, Data Ingestion, Transformation, Visualization, Data Governance, Data Storage, Cloud & Infrastructure
Core Skills - SQL, Python, Spark, Databricks, Azure, ELT, Docker
Projects
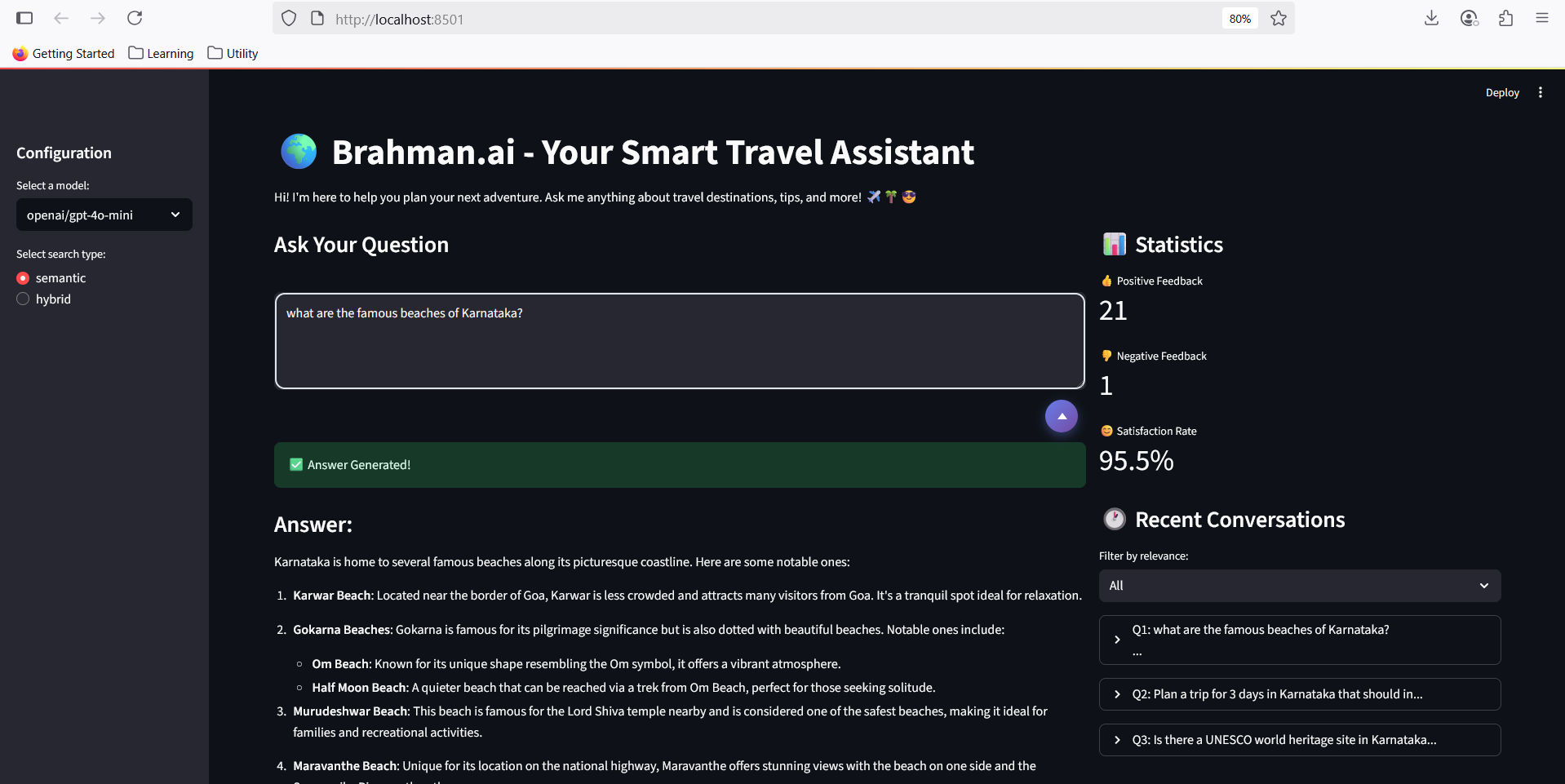
Brahman.ai - Your Smart Travel Assistant
I built advanced Retrieval-Augmented Generation (RAG) platform for seamless travel planning and destination exploration

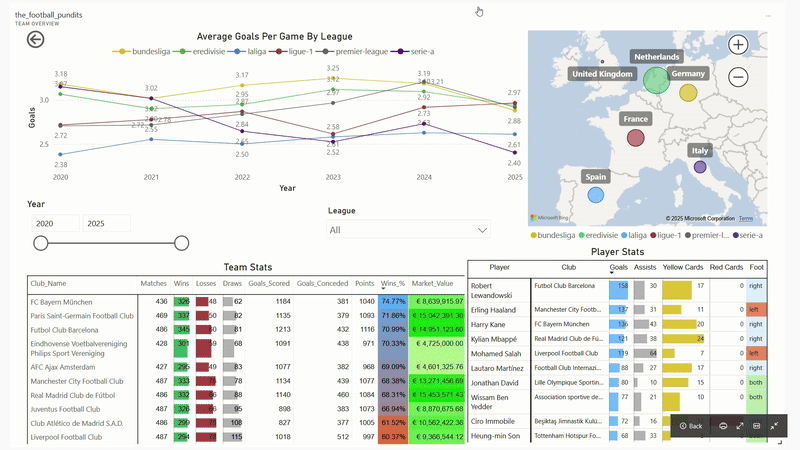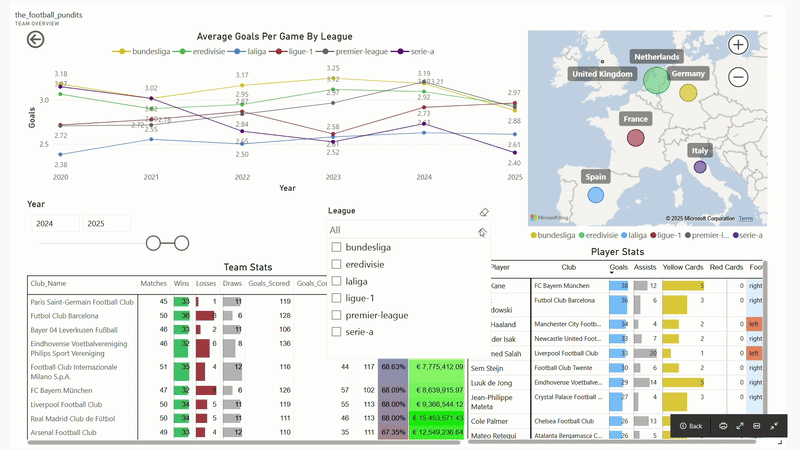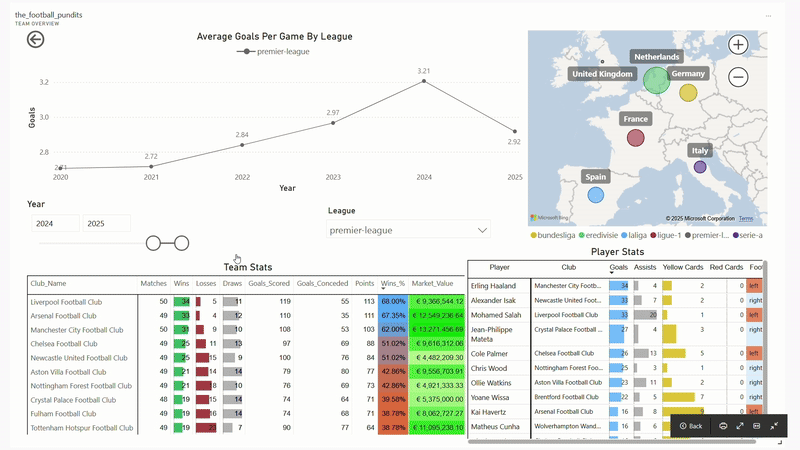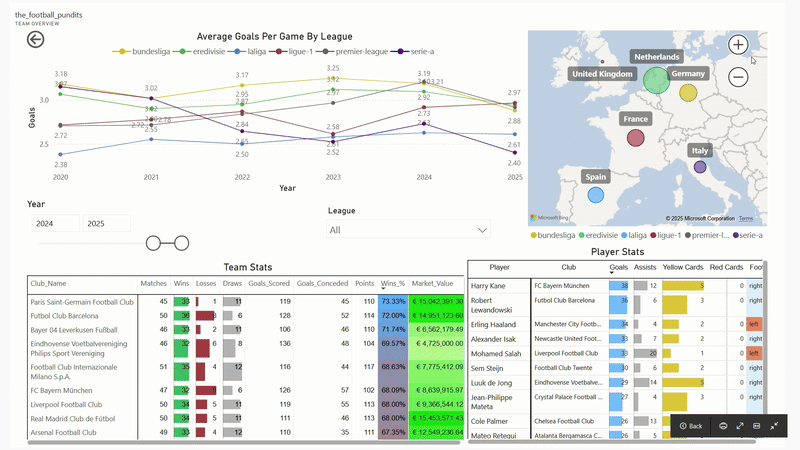
The Football Pundits: Decoding the beautiful game
I built full-fledged end-to-end data pipeline from scratch that feeds into interactive PBI dashboard
Articles
Building a Cloud-Native Commercial Data Platform for TskPharma
Designing End-to-End Infrastructure for Pharmaceutical Analytics
Executive Summary
This case study examines the design and implementation of a comprehensive commercial data infrastructure for TskPharma, a pharmaceutical company preparing to launch an oncology drug. The project addressed the challenge of building enterprise-grade data and analytics capabilities from the ground up, integrating both traditional business intelligence and cutting-edge AI technologies to support commercial operations.
Situation Analysis
TskPharma faced several critical challenges as they prepared for their drug launch:
Infrastructure Gap: StarNet Global partnered with TskPharma, a pre-launch pharmaceutical client preparing to introduce an oncology drug to market. The client required a complete commercial data management and analytics solution to support their go-to-market strategy.
Absence of IT Foundation: TskPharma lacked any existing IT infrastructure or data systems. This presented both a challenge and an opportunity to build a modern, cloud-native platform without legacy system constraints.
Regulatory Compliance Requirements: As a pharmaceutical company handling prescription data and patient information, TskPharma needed to ensure HIPAA compliance, data privacy protections, and audit trail capabilities from day one of operations.
Resource Constraints: With a limited initial technical team and tight timelines driven by the drug launch schedule, the solution needed to be implementable quickly while remaining maintainable by a small team.
Scalability Imperatives: The infrastructure needed to support initial launch operations while being architected to scale significantly as market presence expanded across territories and data volumes increased.
Business and Technical Challenges
The project presented multiple interconnected challenges that required careful architectural consideration:
Zero Baseline Infrastructure: TskPharma had no existing IT systems, data warehouses, analytics platforms, or cloud environments. Every component needed to be designed, provisioned, and configured from scratch while ensuring enterprise-grade reliability.
Dual Data Paradigm: The solution needed to handle fundamentally different types of data with distinct processing requirements. Structured prescription transactions, physician profiles, and sales data required traditional data warehousing approaches, while unstructured clinical documents, research papers, and medical images demanded modern AI and semantic search capabilities.
Rapid Deployment Timeline: With the drug launch date approaching, the infrastructure needed to be operational within months rather than years, requiring careful prioritization and phased delivery while maintaining quality standards.
Cost Optimization Balance: As a pre-launch company, TskPharma needed to control infrastructure costs carefully while building a platform capable of supporting significant growth. The architecture needed to provide enterprise capabilities without enterprise-scale initial spending.
Multi-Source Data Integration: The platform needed to ingest data from numerous pharmaceutical data vendors, each with different formats, delivery schedules, and data quality characteristics. Creating a unified view across these disparate sources while maintaining data lineage presented significant integration challenges.
Compliance and Governance: Pharmaceutical data requires strict access controls, comprehensive audit trails, and adherence to industry regulations. These governance requirements needed to be embedded into the platform architecture rather than added as afterthoughts.
AI Integration Complexity: Incorporating artificial intelligence capabilities for semantic search and question answering required expertise in both traditional data engineering and modern machine learning operations, along with specialized pharmaceutical domain knowledge.
Solution Design
What infrastructure components and system specifications are required?
TskPharma requires a cloud-native platform that handles both traditional analytics and modern AI capabilities. The infrastructure centers around Azure services with everything provisioned through Terraform, which allows setup of the entire environment with minimal resources and in very short timeframes.
The foundation uses Azure Data Lake Storage Gen2 for all raw and processed data, Databricks for distributed processing, and PostgreSQL for metadata management. What makes this architecture effective is the lakehouse design that combines flexible storage with database capabilities. For the AI components, we deploy Qdrant vector database on Kubernetes for semantic search and run Small Language Models on Azure compute for pharmaceutical-specific question answering.
The key architectural insight involves running two parallel pipelines in a unified infrastructure. Structured prescription data flows through a Medallion Architecture with Bronze, Silver, and Gold layers where it gets progressively cleaned and aggregated into business metrics. Unstructured documents like images, videos, patient reports and clinical research papers follow an embedding pipeline involving document extraction, semantic chunking, and embedding generation. Both pipelines converge at the Streamlit user interface where users access everything through a single web application. Governance integrates throughout all layers with monitoring provided by Grafana and Evidently AI. The entire infrastructure can be deployed via Terraform on Azure cloud.
Technology Stack: Our technology stack combines cutting-edge data engineering and AI/ML tools with robust infrastructure components. For data ingestion and processing, Azure Data Factory orchestrates data movement while Databricks handles distributed processing. LangChain Text Splitters manage OCR, PDF parsing, and video transcription for unstructured content. Storage and data platforms include Delta Lake for ACID transactions, PostgreSQL for metadata management, and Qdrant as the vector database for semantic search capabilities. Data transformation happens through DBT for SQL-based transformations and PySpark for large-scale distributed processing. The AI and ML frameworks include LangChain for orchestration, Small Language Models like BioMistral-7B and Phi-3-medical for pharmaceutical-specific intelligence, Clinical-Longformer for long document understanding, and embedding models from Jina AI and BioMistral for semantic representations. Governance and security leverage Azure Active Directory for identity management, Multi-Factor Authentication for access protection, Immuta for dynamic data masking, and Great Expectations for data quality validation. Visualization happens through Streamlit for the unified web application and Power BI for enterprise reporting. Infrastructure provisioning uses Terraform for infrastructure as code, Azure Kubernetes Service for containerized workloads, Azure DevOps for CI/CD pipelines, and Azure Monitor with Application Insights for observability. Finally, monitoring employs Grafana for operational metrics visualization, Evidently AI for ML model performance tracking, and Guardrails for validating compliance of AI-generated content.
How should the data architecture be designed and defined?
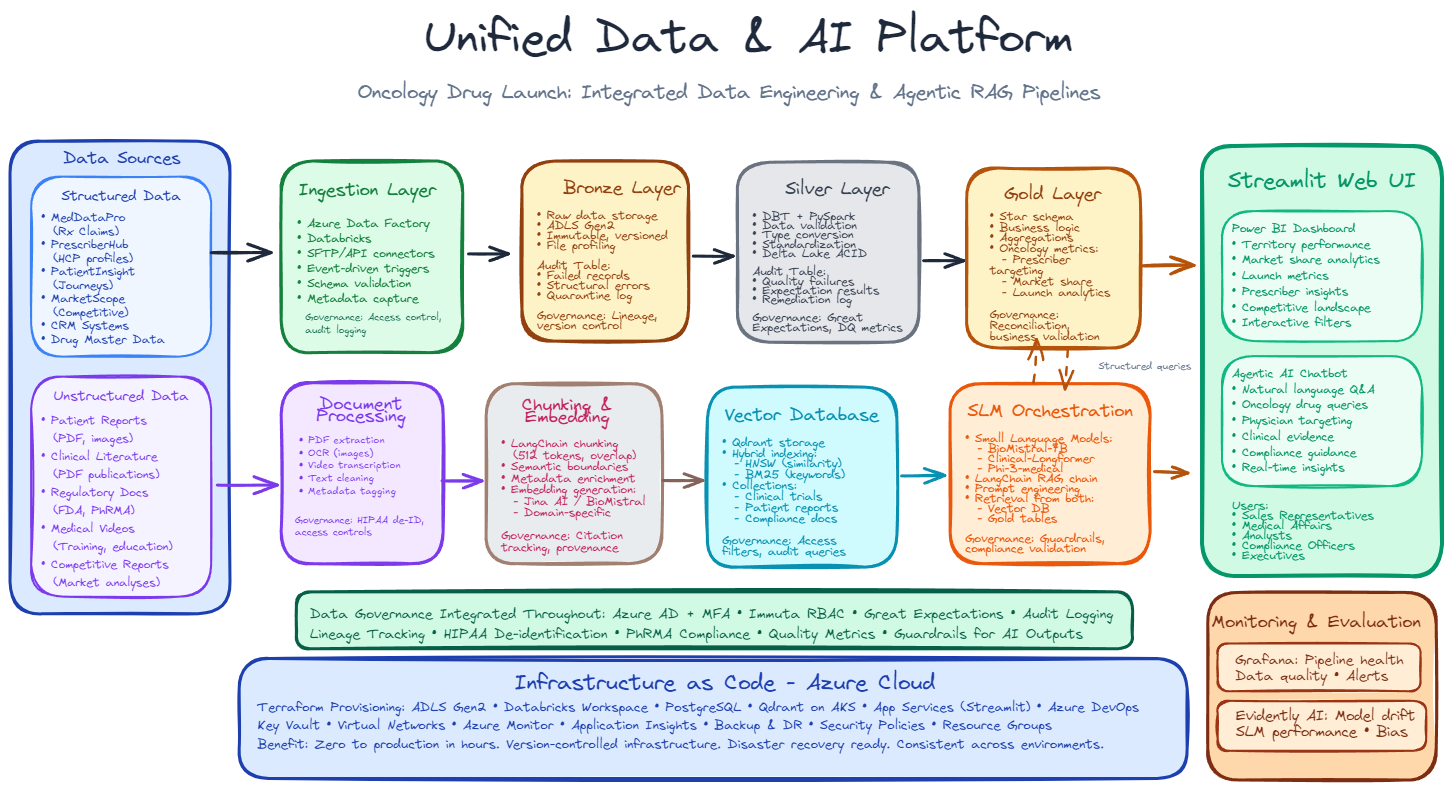
Figure: Unified Data & AI Platform - Integrated Data Engineering & Agentic RAG Pipelines
The architecture recognizes a fundamental truth about pharmaceutical data: prescription transactions and clinical documents require fundamentally different handling approaches. Attempting to force both through a single processing pipeline would compromise the effectiveness of both.
The structured data pipeline implements medallion architecture with three progressive layers. Bronze preserves raw vendor files exactly as received, creating an immutable audit trail. This layer accepts data from prescription claims processors, physician profiling services, and market research vendors without transformation, maintaining complete fidelity to source systems. Silver applies validation, standardization, and type conversion to create technically correct datasets. Data quality checks identify and quarantine records failing business rules, vendor identifiers map to common keys enabling cross-source joins, and data types convert from text to appropriate formats. This layer produces clean, standardized datasets ready for business logic application. Gold applies business logic and dimensional modeling to create analytics-ready tables optimized for specific use cases. Raw prescriptions become market share metrics, sales territories receive performance calculations, and physician profiles enrich with prescribing behavior analytics. This progression works effectively for prescription claims, physician profiles, and market data because these datasets benefit from progressive transformation from raw records to business metrics.
The unstructured pipeline bypasses medallion layers entirely because images, videos, clinical papers and patient reports do not benefit from that progression. Instead, documents flow through extraction to obtain text from PDFs and images, chunking to break long documents into semantically meaningful passages, embedding generation to create mathematical representations of meaning, and storage in a vector database optimized for similarity search. This pathway enables semantic retrieval where users ask questions in natural language and receive contextually relevant document passages in response.
Both pipelines converge at the Small Language Model orchestration layer. When users ask questions requiring both prescription numbers and clinical evidence, the orchestration retrieves from Gold tables and the vector database simultaneously, then synthesizes integrated answers. From the user perspective in Streamlit, this happens transparently as a single conversational interface. For monitoring and evaluating model behavior and user queries, we employ Evidently AI and Grafana tools.
Data governance integrates into every processing stage rather than being added afterward. The ingestion layer enforces access controls and logs all data movement. Bronze and Silver maintain audit tables capturing failed records and quality issues. Vector database access filters based on user roles. Small Language Model outputs flow through Guardrails that validate compliance with pharmaceutical regulations before users see responses. Role-based access control and multi-factor authentication control platform access. Immuta provides dynamic masking so the same Gold table shows different levels of detail depending on whether a sales representative or analyst queries it. Great Expectations validates data against hundreds of business rules at each layer transition. Every query and data access gets logged for regulatory audit trails.
What is the recommended data model and why should it be adopted?
Gold layer implements star schema dimensional modeling because this pattern optimizes for how pharmaceutical teams actually formulate questions. A central prescriptions fact table contains measures like prescription count, market share percentage, and revenue estimates. Dimension tables for time, physician, geography, product, and payer surround the fact table providing business context. This model proves effective because queries naturally filter and group by dimensions. Requests like "show me market share by territory and month" become straightforward joins between the fact table and geography and time dimensions. The denormalized structure means fewer joins than normalized designs, which translates directly to faster query performance on large datasets.
We build multiple gold tables serving different purposes rather than one monolithic model. A sales performance mart aggregates by representative and territory with daily refresh. A market intelligence mart focuses on competitive benchmarking with weekly refresh. A compliance mart maintains detailed interaction history with strict access controls. Each optimizes for its specific analytical purpose.
Clinical literature and medical documents utilize an entirely different model based on semantic embeddings. Each document chunk becomes a high-dimensional vector capturing its meaning. Similar content clusters together in this mathematical space regardless of exact wording. This enables semantic search where someone asking about treatment resistance finds relevant passages even if they use different terminology than the original documents.
The key architectural insight recognizes that we need both models working together. Star schema answers analytical questions about numbers and trends. Vector embeddings answer contextual questions about clinical evidence and guidelines. The Small Language Models bridge these approaches, pulling from both as needed to provide integrated answers to complex business questions.
How should different layers in the data model be structured and function?
We follow a Medallion Architecture where Bronze serves as the immutable landing zone where vendor data arrives exactly as delivered. Prescription files from MeddataPro, physician profiles from Prescribershub, and patient journey data from PatientInsight all land in Bronze unchanged. We partition by source system and date making it straightforward to reprocess specific time periods. Audit tables capture any files failing basic structural checks. Preserving original files allows us to reprocess with improved logic without requesting vendor redeliveries and facilitates data reconciliation.
Silver transforms bronze data into technically correct standardized datasets. CSV and JSON files become Delta Lake tables with typed columns. Great Expectations runs comprehensive validation ensuring prescription dates fall within expected ranges and drug codes exist in reference data. Records failing validation go to quarantine audit tables for manual review rather than corrupting downstream processing. Standardization maps different vendor identifiers to common keys so we can join across sources reliably. The grain stays atomic preserving flexibility for different aggregation patterns downstream.
Gold applies business logic and dimensional modeling to create analytics-ready tables. Raw prescriptions become market share metrics, growth rates, and territory attainment scores. Star schemas organize data into facts and dimensions optimized for common query patterns. Multiple gold tables serve different business functions with appropriate aggregation levels and refresh frequencies. This is where data becomes directly usable for decision making.
Documents bypass medallion layers because they need different handling. The document processing stage extracts text from PDFs, applies OCR to images, and transcribes videos into searchable text with help from Langchain framework text splitters and markdown capabilities. Text cleaning standardizes formatting. Entity extraction identifies drug names, diseases, and outcomes that become metadata tags. Chunking breaks long documents into passages typically around five hundred tokens with overlap between adjacent chunks. This granularity works well with embedding models and retrieval systems. Each chunk carries metadata about source document, position, publication date, document type, and extracted entities. Embedding generation creates vector representations using pharmaceutical domain-specific models. Chunks about similar clinical concepts end up with similar embeddings even if wording differs. These vectors go into Qdrant organized into collections by document type enabling filtered retrieval. The entire flow optimizes for semantic search. When users ask questions, we find the most relevant document passages based on meaning rather than just keyword matching.
How can we ensure data quality is consistently maintained?
Quality gates exist at each layer transition preventing bad data from propagating. Bronze ingestion validates file structure, checksums, and basic format compliance. Files failing these checks quarantine immediately with detailed error logging in audit tables. Silver transformation runs Great Expectations suites with hundreds of business rule checks. Records violating expectations go to audit tables rather than main tables. Gold business logic includes reconciliation checks ensuring aggregates sum correctly and metrics fall within expected ranges.
The audit tables in Bronze and Silver provide transparency into quality issues. Data stewards review quarantined records daily, applying remediation workflows that might involve contacting vendors, enriching reference data, or applying correction rules. This manual review catches issues automated validation misses while the quarantine mechanism prevents bad data from reaching production dashboards.
Grafana dashboards track data quality metrics in real time. Validation pass rates, record counts, processing durations, and completeness percentages all visualize with trend analysis. Alerting rules trigger when quality drops below thresholds or when anomalies appear. Critical alerts go to PagerDuty for immediate response. Warning alerts post to Slack channels. This proactive monitoring catches degrading quality before business users notice problems.
Evidently AI monitors the machine learning components specifically. As users interact with the chatbot, it tracks whether Small Language Models maintain consistent performance, whether embedding quality stays high, and whether data drift occurs in query patterns. This ML-specific monitoring ensures AI-powered features remain trustworthy as usage scales.
Every processing component includes embedded governance controls rather than treating governance as a separate concern. Ingestion logs all data movement with timestamps and checksums. Processing tracks lineage showing which Gold tables derive from which Silver tables from which Bronze files. The vector database logs all queries with user identity and retrieved content. Small Language Model outputs flow through Guardrails validating pharmaceutical compliance before reaching users. This integrated approach makes governance visible and actionable at each stage rather than being abstract policy nobody follows.
What best practices should be implemented in this architecture?
The major challenge with TskPharma was having no IT infrastructure setup. Instead of manually configuring systems, we build the entire infrastructure in Terraform as Infrastructure as Code. Every Azure resource gets defined in version-controlled Terraform configurations. Storage accounts, Databricks workspaces, databases, networking, security policies, and monitoring systems all exist as code. This approach transforms infrastructure from manual configuration into repeatable deployments. Need a development environment matching production? Run Terraform and complete setup in hours. Need disaster recovery? Restore data backups and run Terraform to recreate infrastructure. This eliminates configuration drift and creates natural documentation since anyone can read the Terraform files to understand exactly how everything is configured. The best part: any service or module you do not want can be disabled or removed to reduce operating costs.
Streamlit hosts both Power BI dashboards and the Agentic AI chatbot in a single web application. Users authenticate once and access everything they need without switching applications. This simplicity drives adoption because sales representatives are not navigating multiple systems with different interfaces. The unified experience also simplifies development and maintenance since we deploy and monitor one application rather than separate systems.
Hosting pharmaceutical-specific models like BioMistral-7B directly in Azure rather than calling external APIs fundamentally changes economics. Users can ask thousands of questions daily without accumulating per-token charges. The models provide better accuracy on medical queries because they trained specifically on biomedical literature. Everything stays within TskPharma's environment addressing data privacy and compliance concerns that external API calls cannot fully resolve.
Pipelines process only new or changed data rather than full refreshes wherever possible. DBT incremental models append transactions rather than rebuilding entire fact tables. Delta Lake merge operations update only changed dimension records. Vector embeddings regenerate only for modified documents. This incremental approach keeps processing windows manageable as data volumes grow.
DBT models include inline documentation explaining business logic. Great Expectations suites document data quality rules as executable tests. Terraform configurations serve as infrastructure documentation. Architecture decision records capture why we made specific design choices. This documentation creates institutional knowledge that survives team changes and enables new engineers to understand the platform quickly.
How should data refresh work in cases of restatement and re-runs?
When vendors deliver restated data correcting historical issues, new versions land in Bronze alongside original versions rather than overwriting. Metadata tracks which version is currently active for downstream processing. This versioning creates complete audit trails showing exactly what changed and when. The restatement workflow starts with impact analysis comparing original versus restated data. Automated reports quantify how many records changed, which metrics are affected, and which dashboards need updates. Data stewards review impact with business stakeholders before proceeding. If impact seems unexpectedly large, investigation happens before accepting restated data.
Processing then flows through a parallel candidate schema rather than immediately updating production. Silver and Gold transformations execute against restated Bronze data writing to staging tables. Business users review candidate data in test environments. Automated reconciliation checks verify totals match vendor control figures and changes align with known issues being corrected.
After validation approval, production cutover happens during a scheduled maintenance window. Metadata updates mark restated Bronze versions as active. Silver layer merge operations incorporate restated records using Delta Lake's atomic transaction capabilities. Gold tables recompute affected partitions incrementally. Power BI datasets refresh. Vector embeddings regenerate for any modified content. Post-cutover validation confirms everything completed successfully. Throughout this process, audit tables document exactly what changed at each layer. Users receive communication explaining what data was restated and how historical reports might differ from previous versions. Dashboard annotations mark time series where restatements occurred so viewers understand context.
The medallion architecture inherently supports re-runs because layers separate concerns cleanly. Bronze preserves immutable source data. Silver applies technical transformations. Gold applies business logic. Changes to business logic only require reprocessing Gold without touching Bronze or Silver. Changes to validation rules require reprocessing Silver and Gold but not Bronze. This separation minimizes reprocessing scope when logic evolves. Delta Lake time travel feature provides additional safety. If reprocessing introduces unexpected issues, we can query prior versions or restore tables to earlier states. This rollback capability reduces risk when updating critical tables that feed executive dashboards.
What are the key risks and mitigation strategies?
As users interact with the chatbot over time, query patterns may shift into topics the models were not extensively trained on. Pharmaceutical knowledge also evolves as new clinical evidence emerges. Evidently AI monitoring detects when model performance degrades by tracking response quality metrics and data drift indicators. Mitigation involves periodic retraining on updated pharmaceutical literature and fine-tuning on representative user queries collected with appropriate privacy protections.
Despite Guardrails validation, the Small Language Models might occasionally generate responses making unapproved promotional claims or omitting required safety information. Comprehensive logging enables retrospective audit of all chatbot interactions. Regular compliance reviews sample conversations checking for violations. User training emphasizes the chatbot provides informational support but does not replace approved promotional materials. The risk never fully disappears with generative AI but these controls reduce probability and enable rapid response if issues arise.
Complex platforms can develop knowledge concentration where one or two people understand critical components. Mitigation includes comprehensive documentation, code review requiring multiple approvers, knowledge sharing sessions, and cross-training rotations. Relationships with external consultants familiar with the architecture provide insurance during transitions.
Cloud platforms occasionally experience regional outages affecting availability. Critical data needs during outages require cached data in Power BI import mode and contingency processes for essential operations. Cross-region disaster recovery capabilities enable failover for prolonged outages. Service level agreements with Azure establish accountability. Thoughtful architecture and operational planning minimize business impact.
Conclusion
The TskPharma commercial data platform demonstrates how modern cloud-native architecture can deliver enterprise-grade capabilities for pharmaceutical analytics while remaining practical for resource-constrained organizations. By combining traditional data warehousing with cutting-edge AI capabilities in a unified infrastructure, the solution provides both immediate operational value and long-term scalability.
The success of this architecture relies on several key principles: treating different data types with appropriate techniques rather than forcing one approach for everything, embedding governance and quality controls throughout rather than adding them afterward, leveraging Infrastructure as Code for repeatability and documentation, and choosing technologies that optimize total cost of ownership rather than just initial implementation cost.
This case study offers a blueprint for pharmaceutical companies seeking to build modern data platforms that support both traditional analytics and emerging AI capabilities while maintaining the compliance and governance requirements inherent to the healthcare industry.